¡Hola!
Esta es la última parte de esta serie sobre la revolución de la credibilidad.
En cierto modo, con esto terminaría el primer capítulo de mi segundo libro. Es la parte en la que más batallé, porque es la que conecta el capítulo 1 con el resto del libro.
La idea es esta: No hay un libro de Diferencias en Diferencias en español porque es un área que está avanzando muy rápido en los últimos años, pero es algo en lo que yo creo que no nos podemos quedar atrás en otras partes del mundo. Es demasiado importante: es la forma en la que estamos evaluando nuestros programas y debemos poder hacerlo bien.
Así que esta es mi forma de avanzar en ese frente 10x más rápido. En lugar de que empecemos a ver libros al respecto en 10 años, estamos viendo los avances por partes HOY. Con tu apoyo, claro está.
Anyway... Me tardé un poco más de lo esperado en esta parte porque no lograba llegar al punto. Pero si algo te puedo decir es que esta es la mejor explicación en español o en inglés que he visto sobre los avances de DD. Es el atajo para estar en la línea junto con los econometristas más avanzados DEL MUNDO. No estoy exagerando: realmente lo creo.
Disfruta.
Los métodos de Diferencias en Diferencias han cambiado mucho desde los tiempos del estudio de David Card en Miami.
El problema surgió porque investigadores en el área de econometría se han dedicado a hacerle ingeniería inversa a los estimadores y han encontrado complejidades adicionales a algo que parecía muy sencillo e intuitivo. El modelo 2x2 que discutimos anteriormente es uno de los más populares para hacer investigación aplicada. Casi una tercera parte de los artículos de economía aplicada en el NBER de los últimos años usaron Diferencias en Diferencias (Goldsmith-Pinkham, 2024).
Pues resulta que Diferencias en Diferencias ni es simple, ni es intuitivo, ni es tan fácil de entender como al inicio parece.
Sumado a esto, la profesión de economista ha pasado de ser sólo teoría a una disciplina empírica (Hamermesh, 2013), por lo que las herramientas para la evaluación econométrica creíble sigue y seguirá creciendo.
Pero lo más importante: los datos no siempre se ajustan al modelo canónico. Por eso es necesario adaptar los modelos para que se puedan aplicar a la realidad.
Roth, et al. (2023) identifican tres diferentes formas en las que se relajan los supuestos estándar del modelo de Diferencias en Diferencias:
- Múltiples periodos y variación en el periodo de tratamiento.
- Posibles violaciones al supuesto de las tendencias paralelas.
- Se separan del supuesto de observar a una muestra de muchos clusters independiente que se toman de una super-población.
Son estas las desviaciones que han hecho que la discusión se haya enriquecido tan fuertemente en los últimos años —y que entrar en el mundo de las diferencias en diferencias se convierta en una confusión. Rápidamente dejamos atrás el mundo en el que hacer DD era un proceso sencillo que sólo se trataba de encontrar un buen experimento natural y aplicar un modelo de efectos fijos de dos vías.
Esto es bueno y malo.
Bueno, porque ahora podemos usar DD para situaciones más complejas con múltiples periodos y relajando los supuestos canónicos de tendencias paralelas. Malo porque tenemos que ser más cuidadosos al momento de estimar nuestros errores estándar.
Múltiples periodos y variación en el tiempo de tratamiento
Para hacer un modelo de DD 2x2 solamente necesitas un antes y un después.
Pero la realidad es más sucia.
Las políticas no se implementan para todos al mismo tiempo. Un estado adopta una ley en 2010, otro en 2012, y un tercero en 2015. Esto se conoce como tratamiento escalonado (staggered adoption).
La reacción natural de cualquier economista fue decir: "¡Más datos! ¡Mejor!". Y aplicar el mismo modelo de siempre: una regresión con efectos fijos de dos vías (TWFE, por sus siglas en inglés). Parecía lógico. Controlas por unidades (estados) y por tiempo (años) y dejas que la variable de tratamiento te dé la respuesta.
ERROR.
Aquí es donde la "revolución" explotó. Investigadores como Goodman-Bacon (2018) y de Chaisemartin & D'Haultfoeuille (2019) metieron las manos en el motor del TWFE y descubrieron algo espantoso.
El estimador TWFE, cuando hay tratamiento escalonado, es un promedio ponderado de todas las posibles comparaciones 2x2 que puedes hacer con tus datos. El problema es que algunas de esas ponderaciones son NEGATIVAS.
¿Qué significa esto? Significa que el modelo empieza a hacer comparaciones que no tienen ningún sentido. En particular, empieza a usar a las unidades que YA FUERON TRATADAS como grupo de control para las unidades que se tratan después.
Piensa en lo absurdo que es eso. Estás usando un grupo cuyo resultado ya está afectado por la política para medir el efecto de esa misma política en otro grupo. Es como intentar medir la estatura de alguien usando una regla que se encoge.
La consecuencia es brutal: si los efectos del tratamiento no son iguales para todos y a lo largo del tiempo (y NUNCA lo son), estas ponderaciones negativas pueden contaminar tu resultado. Puedes obtener un efecto negativo cuando todos los efectos reales son positivos. O puedes obtener un efecto cero cuando en realidad hay un impacto enorme.
Tu modelo te está mintiendo a la cara.
Es como el chiste de los tres econometristas. Uno dispara a la derecha, otro a la izquierda, y el tercero grita "¡Le dimos!". El estimador TWFE es ese tercer economista.
La solución fue dejar de usar al tercer economista.
Investigadores como Callaway & Sant’Anna (2018), Sun & Abraham (2018), Borusyak, Jaravel, & Spiess (2024) y Gardner (2022) crearon nuevos estimadores que son más inteligentes. En lugar de promediar todo a lo loco, estos métodos identifican las comparaciones "limpias" (tratados vs. nunca tratados, o tratados vs. aún no tratados) y descartan las comparaciones "sucias" (las que generan ponderaciones negativas).
El resultado es una estimación del efecto del tratamiento en la que sí puedes confiar.
Tendencias no-paralelas
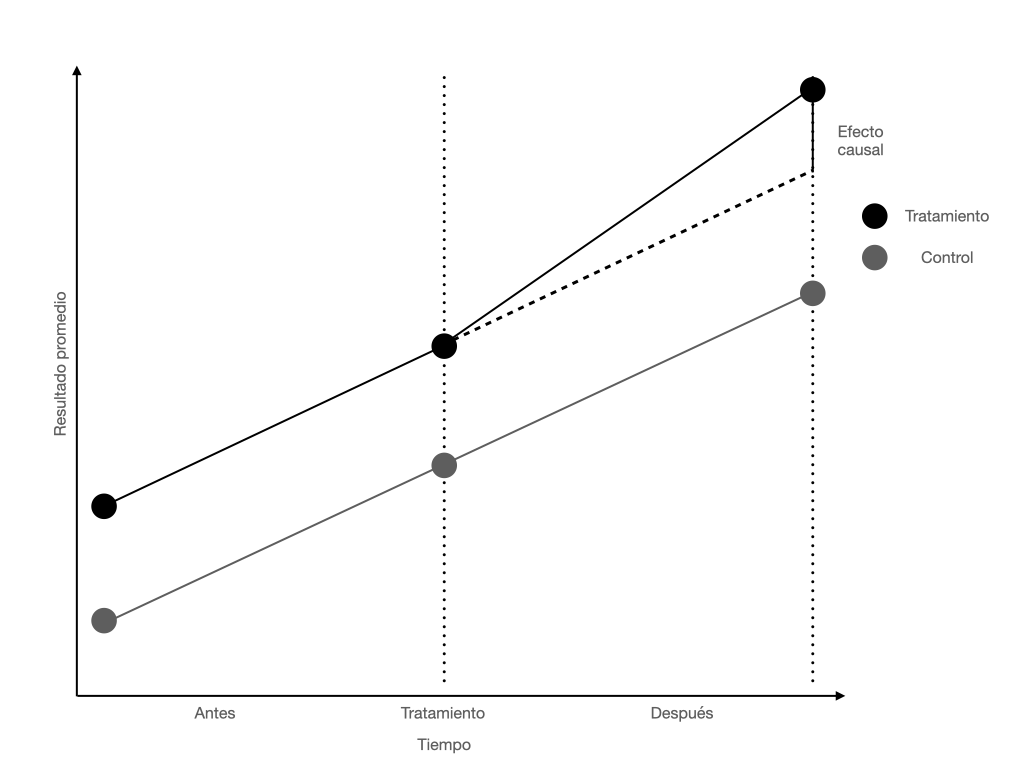
El supuesto clave de CUALQUIER modelo de Diferencias en Diferencias es el de tendencias paralelas. La idea es que, si no hubiera habido tratamiento, el grupo de tratamiento y el de control se habrían comportado de la misma manera.
$$ E[Y_{g_1,2}(0) - Y_{g_1,1}(0)] = E[Y_{g_0,2}(0) - Y_{g_0,1}(0)] $$
Gráficamente, sus líneas de tendencia son paralelas antes del tratamiento. Si no lo son, todo el modelo se derrumba. Tu grupo de control no sirve para nada y tus resultados son basura.
Pero, ¿qué pasa si las tendencias no son perfectamente paralelas? ¿Tiramos todo a la basura?
No necesariamente. Aquí es donde entran los métodos más sofisticados.
El más conocido es Diferencias en Diferencias Sintético (Arkhangelsky et al., 2021). La idea es brillante en su simplicidad: si no puedes encontrar un buen grupo de control, ¡constrúyelo!
En lugar de comparar tu unidad tratada con el promedio simple de todas las unidades no tratadas, el método sintético crea un "clon" de tu unidad tratada. Lo hace buscando una combinación ponderada de unidades de control que replique la tendencia pre-tratamiento de tu unidad tratada. Esencialmente, construyes un contrafactual casi perfecto.
Este método es increíblemente poderoso porque te permite ser creíble incluso cuando no tienes un grupo de control obvio.
Es la respuesta para cuando la realidad no te da un experimento natural limpio en bandeja de plata.
Supuestos alternativos en el muestreo
Este punto es más técnico, pero igual de importante. Se trata de cómo calculas tus errores estándar.
Un error estándar te dice cuánta confianza puedes tener en tu estimación. Un error estándar pequeño significa que estás bastante seguro; uno grande significa que tu resultado podría ser pura suerte.
Los métodos clásicos asumen cosas muy convenientes sobre tus datos: que tienes muchos grupos, que son independientes entre sí, etc. Pero en muchas aplicaciones, especialmente en políticas públicas, tienes pocos grupos tratados (a veces solo uno) y los errores pueden estar correlacionados de formas extrañas.
Si calculas mal tus errores estándar, tus p-values y tus intervalos de confianza son inútiles. Podrías estar publicando un artículo sobre un efecto "estadísticamente significativo" que en realidad es solo ruido. ES UNA DE LAS FORMAS MÁS FÁCILES DE ENGAÑARSE A SÍ MISMO.
La literatura moderna de DD ha puesto un énfasis enorme en esto. Los nuevos paquetes de software para estimadores como los de Callaway & Sant’Anna no solo te dan una estimación robusta del efecto, sino que también implementan procedimientos (como el bootstrap) para calcular errores estándar que son válidos en una gama mucho más amplia de escenarios.
La lección es clara: no basta con obtener el coeficiente correcto. Tienes que saber cuán preciso es ese coeficiente. Ignorar la estructura de tus datos al calcular la incertidumbre es negligencia metodológica.
Referencias
Arkhangelsky, D., Athey, S., Hirshberg, D. A., Imbens, G. W., & Wager, S. (2021). Synthetic Difference-in-Differences. American Economic Review, 111(12), 4088–4118. https://doi.org/10.1257/aer.20190159
Baker, A. C., Larcker, D. F., & Wang, C. C. Y. (2022). How much should we trust staggered difference-in-differences estimates? Journal of Financial Economics, 144(2), 370–395. https://doi.org/10.1016/j.jfineco.2022.01.004
Borusyak, K., Jaravel, X., & Spiess, J. (2024). Revisiting Event-Study Designs: Robust and Efficient Estimation. The Review of Economic Studies, 91(6), 3253–3285. https://academic.oup.com/restud/article/91/6/3253/7601390
Callaway, B., & Sant'Anna, P. H. C. (2018). Difference-in-Differences with Multiple Time Periods. arXiv preprint arXiv:1803.09015.
de Chaisemartin, C., & D'Haultfoeuille, X. (2019). Two-Way Fixed Effects Estimators with Heterogeneous Treatment Effects (Working Paper No. 25904). National Bureau of Economic Research. https://www.nber.org/system/files/working_papers/w25904/w25904.pdf
Goldsmith-Pinkham, P. (2024). Tracking the Credibility Revolution across Fields. arXiv preprint arXiv:2405.20604.
Gardner, J. (2022). Two-stage difference-in-differences. arXiv preprint arXiv:2207.05943.
Goodman-Bacon, A. (2018). Difference-in-Differences with Variation in Treatment Timing (Working Paper No. 25018). National Bureau of Economic Research. https://www.nber.org/system/files/working_papers/w25018/w25018.pdf
Hamermesh, D. S. (2013). Six Decades of Top Economics Publishing: Who and How? Journal of Economic Literature, 51(1), 162–172. https://doi.org/10.1257/jel.51.1.162
Roth, J., Sant’Anna, P. H. C., Bilinski, A., & Poe, J. (2023). What’s trending in difference-in-differences? A synthesis of the recent econometrics literature. Journal of Econometrics, 235(2), 2218–2244. https://doi.org/10.1016/j.jeconom.2023.03.008
Sun, L., & Abraham, S. (2018). Estimating Dynamic Treatment Effects in Event Studies with Heterogeneous Treatment Effects. arXiv preprint arXiv:1804.05785.