



Imagina que deseas conocer el efecto de una política pública en la población.
Siempre que sea posible, lo mejor que puedes hacer es hacer un experimento. Pero hay dos problemas:
- Los experimentos son caros y difíciles de implementar, pues implican tener un control sobre todas las variables que podrían alterar el resultado.
- Los resultados de un experimento rara vez son escalables a nivel de una población.
Para colmo, de cualquier manera tendrás que evaluar la efectividad de la política cuando se hace a nivel de una población.
En este post haremos un tutorial para aplicar el modelo de Diferencias en Diferencias usando R.
El ejemplo que usaremos para este tutorial lo puedes encontrar también en el libro Doing Economics del Core Project. Se trata sobre los efectos de un impuesto a las bebidas azucaradas.
Los economistas no prohibimos, le ponemos impuestos a las cosas
A finales de 2014, la ciudad de Berkeley, California votó que le pusieran un nuevo impuesto a las bebidas azucaradas.
El objetivo del impuesto era disminuir el consumo de bebidas que sabemos tienen efectos negativos en la salud de la población. Cuando queremos hacer que el compotamiento de las personas cambie, no ponemos leyes para prohibirlas, les subimos los impuestos con la esperanza de que el aumento de precio haga su trabajo.
Se le llaman impuestos al pecado.
Hay muchos ejemplos de este tipo de impuestos. Hay impuesto a los autos para reducir la contaminación. Impuesto al alcohol y al tabaco, porque también tienen efectos en la salud. Y naturalmente, impuestos a las bebidas azucaradas. Casi todos los países tienen algún impuesto de este tipo, en parte porque es relativamente fácil de aprobar (no siempre tan fácil de implementar).
Para saber si el impuesto funcionó, necesitamos conocer tres cosas
- Si el aumento de los impuestos hizo que los precios subieran. En ocasiones, los precios no se trasladan al consumidor. Las empresas prefieren absorberlo, haciendo que el impuesto no tenga efecto sobre el comportamiento de los consumidores.
- Si los precios subieron, queremos saber si los usuarios redujeron su consumo y qué tanto. En lenguaje de economistas, queremos conocer la elasticidad de los precios.
- Si los consumidores dejaron de tomar estas bebidas, queremos saber si su salud mejoró.
En este tutorial nos quedaremos con el análisis del primer punto.
Paso #1: Descarga y explora la base de datos
Te dejo la base de datos en el siguiente enlace.

Usa el siguiente código para cargar la base de datos y mostrar su estructura.
# Cargar las bibliotecas necesarias
library(readxl)
library(dplyr)
# Definir la ruta del archivo
file_path <- "data/Dataset Project 3.xlsx"
# Cargar la hoja del diccionario de datos
data_dictionary <- read_excel(file_path, sheet = "Data Dictionary")
# Cargar la hoja de datos y mostrar las primeras filas
df <- read_excel(file_path, sheet = "Data")
# Imprimir el diccionario de datos y el encabezado de los datos
print("Data Dictionary:") # Imprimir el diccionario de datos
print(data_dictionary)
print("Data Header:") # Imprimir el encabezado (primeras filas) de los datos
head(df) # Mostrar las primeras filas del conjunto de datos
Alternativamente, puedes usar las funciones de RStudio para cargarlo de manera manual. Si tienes dudas, consulta este curso gratuito que tengo en mi página.
Nota que:
- La variable
taxedes una variable dummy con valores de 0 y 1. Cuandotaxedes igual a 1, significa que el producto si es sujeto a impuesto. Incluso aunque en el periodo del registro sea antes de la implementación. - El tipo de tienda se muestra en
store_type. Hay 4 tipos de tiendas de las que se recolectó la información: Supermercados grandes, supermercados pequeños, farmacias y estaciones de gas. - La variable
timemuestra el momento en que se recolectó el dato. De acuerdo al paper original, los datos se tomaron en Diciembre de 2014, en Marzo de 2015 y en Junio de 2016.
unique(df$time)
- Los productos y las tiendas se registran por un identificador que se muestra en las variables
store_idyproduct_id. También tenemos un poco más de detalles del tipo de producto detallado entypeytype2.
Usa este código y nota que los registros no están balanceados (y también que Junio de 2016 está mal registrado). Esto quiere decir que hay productos que tal vez se registraron antes del impuesto y que desaparecieron después de él. O al contrario, podrían haber productos que aparecieron después del impuesto.
Usa este código para mostrar una tabla de frecuencia que muestra las observaciones por fecha y por tipo de tienda.
# Crear una tabla de contingencia con store_type y time
summary_table <- table(df$store_type, df$time)
# Convertir la tabla a data frame para añadir la columna de Total
summary_table_df <- as.data.frame.matrix(summary_table)
# Añadir una columna 'Total' que suma los valores de cada fila
summary_table_df$Total <- rowSums(summary_table_df)
# Añadir una fila 'Total' que suma todas las filas
summary_table_df["Total", ] <- colSums(summary_table_df)
# Mostrar la tabla resumen
print(summary_table_df)

Medias condicionales
Esta es la versión más sencilla de un modelo de diferencias en diferencias.
Se trata de identificar las medias condicionales de los grupos tratados y sin tratamiento antes y después de la intervención. La idea es que el grupo que no fue tratado funcione como grupo de control en un experimento.
Para que un grupo se pueda considerar de control, las circunstancias del evento tienen que ser muy especiales.
- Tiene que ser muy similar al grupo de tratamiento. En el caso de este impuesto, estamos comparando los productos que están en la misma tienda y que aparecen en los mismos periodos.
- Las circunstancias no deben de dar tiempo para sospechar de algún sesgo de selección. Generalmente, los mejores “experimentos naturales” ocurren de repente. Un accidente natural, o una implementación repentina son ideales, porque no dan tiempo para adaptarse.
Comencemos modificando los datos un poco para cumplir con estos puntos.
La base de datos incluye algunos registros de productos que no aparecen en todos los periodos de registro.
Vamos a filtrarlos.
# Primero, vamos a corregir un error: Debería decir Marzo de 2016 y no de 2015.
df <- df %>%
mutate(time = ifelse(time == "MAR2015", "MAR2016", time)) # Cambiar 'MAR2015' a 'MAR2016'
# Crear la variable 'period_test' indicando si el producto está presente en los tres periodos
dat <- df %>%
group_by(store_id, product_id) %>%
mutate(period_test = all(c("DEC2014", "JUN2015", "MAR2016") %in% time)) %>%
ungroup()
# Mostrar las primeras filas para verificar
table(dat$time)
# Filtrar el conjunto de datos donde period_test es TRUE y supp es 0
dat_c <- subset(dat, period_test == TRUE & supp == 0)
# Mostrar el conjunto de datos filtrado
head(dat_filtered)
table(dat_filtered$time)
Ahora si, estamos listos para calcular las medias condicionales.
El siguiente código crea una tabla con los precios promedio de los productos con impuesto y sin impuesto en los diferentes periodos de tiempo y en los diferentes tipos de tienda.
Lo que estamos buscando en esta tabla es que los precios sean en promedio más altos para los productos con impuesto después de la implementación.
# Calcular la media condicional por taxed, store_type, y time
table_res <- dat_c %>%
group_by(taxed, store_type, time) %>%
summarise(n = n(), avg.price = mean(price_per_oz, na.rm = TRUE), .groups = "drop") %>%
spread(key = time, value = avg.price)
# Mostrar la tabla
print(table_res)
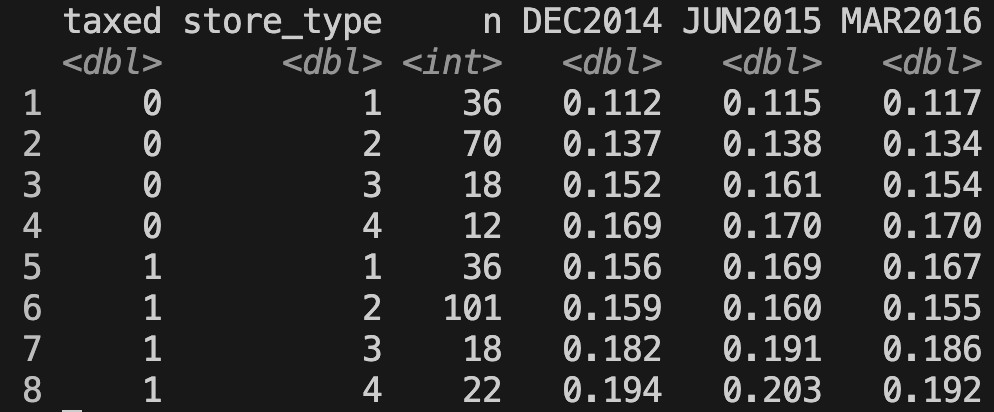
Nuestro grupo de control son las bebidas a las que no se les aplica el impuesto (los que en taxed tienen 0). Si el incremento en los precios se debe al impuesto, entonces el grupo de control no debería de ver un aumento significativo.
Veamos de manera gráfica.
El siguiente código crea columnas adicionales con las diferencias en diferentes periodos en el tiempo. De Diciembre de 2014 a Junio de 2014 y de Diciembre de 2014 a Marzo de 2016.
table_res$D1 <- table_res$JUN2015 - table_res$DEC2014
table_res$D2 <- table_res$MAR2016 - table_res$DEC2014
Lo mejor es mostrarlo de forma gráfica
El siguiente código crea un gráfico de barras con la diferencia en el promedio en los precios de Diciembre a 2014 a Junio de 2015.
# Crear la gráfica para el cambio de precio entre Junio 2015 y Diciembre 2014
ggplot(table_res,
aes(fill = factor(taxed), y = D1, x = factor(store_type))) + # Especificar la variable para el color (fill) y los ejes
geom_bar(position = "dodge", stat = "identity") + # Gráfico de barras con las barras separadas
labs(y = "Cambio en el precio (US$/oz)", x = "Tipo de tienda") + # Etiquetas de los ejes
scale_fill_discrete(name = "Impuestos",
labels = c("No gravado", "Gravado")) + # Etiquetas para la leyenda
ggtitle("Cambio promedio en el precio de Dic 2014 a Jun 2015") # Título de la gráfica
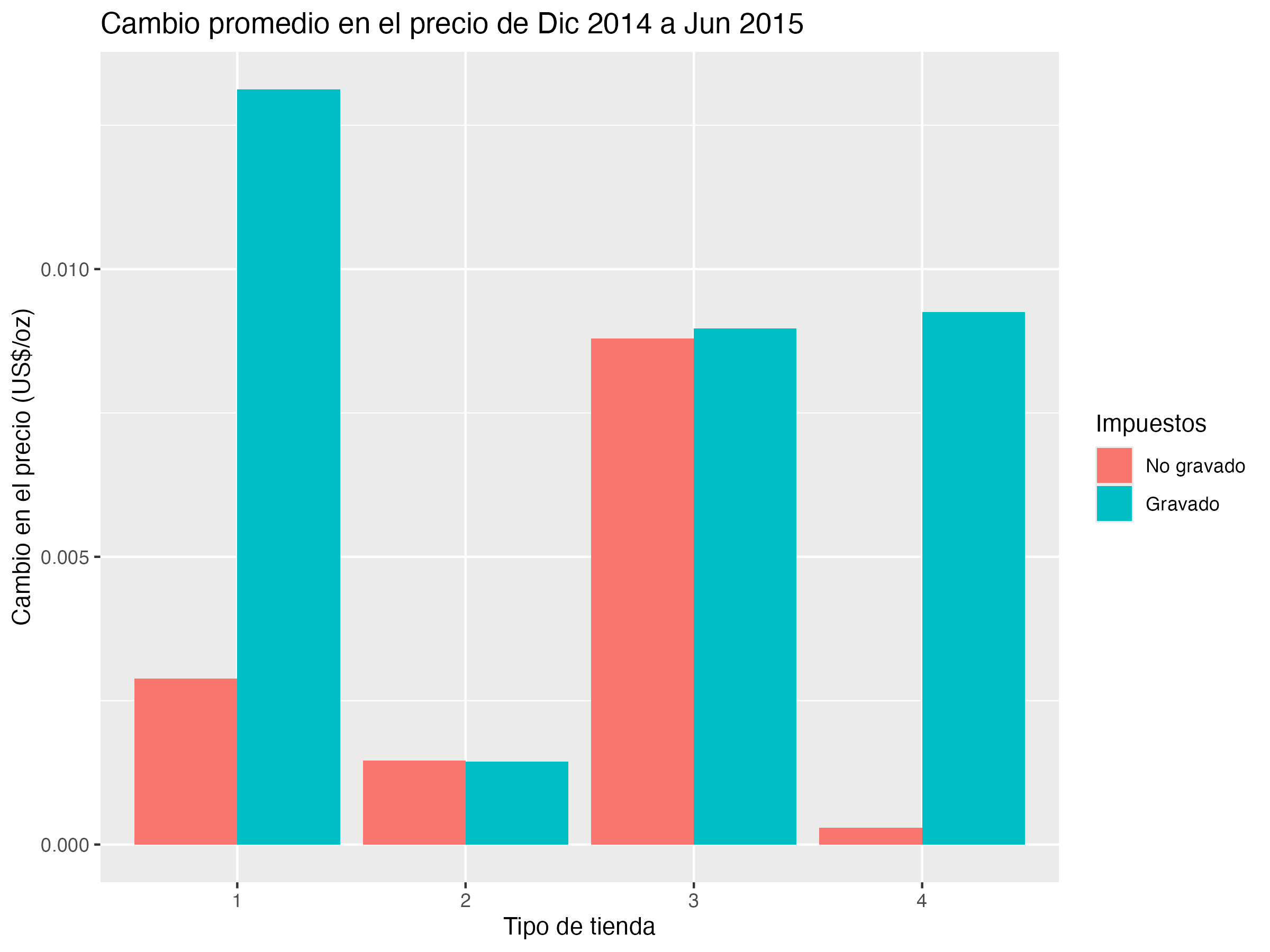
Nota que
- En los supermercados grandes (
store_type = 1) la diferencia en los precios entre los productos gravados y los que no tienen impuesto es muy grande. Lo mismo para las estaciones de gas. - Pero en los supermercados pequeños y las farmacias, el cambio no parece ser significativo.
La forma de ver esto es por la diferencia que hay en las barras. ¿Lo notas? Es la diferencia que hay entre grupos de la diferencia en el tiempo.
Por eso se le llama a la técnica diferencias en diferencias.
¿Apoco así de fácil?
En concepto, si.
Realmente las diferencias en diferencias se complican más en cuanto a encontrar los casos comparables. Cuando las condiciones son favorables, se trata de una simple diferencia de medias.
Pero hay casos un poco más complejos que requieren más interesantes de estadística y causalidad.