


![[Tutorial] Hacer una pirámide de población en R y Python](/content/images/size/w30/2024/11/DALL-E-2024-11-04-18.01.13---A-minimalist-black-and-white-lineart-sketch-of-a-short-robot-carrying-blocks-to-build-a-pyramid.-The-robot-is-compact-and-sturdy--with-simple-geometri.webp)
La mejor forma de mostrar la dinámica de una población es con un gráfico de pirámide.
Se le llama así porque por años esa es la forma que ha tomado, cuando ponemos dos gráficos de barras contiguos. Cada barra es la suma de todas las personas en un rango de edades.
En este tutorial:
- Te daré el código para hacer tus pirámides de población en R y Python.
- Luego veremos un ejemplo real descargando datos del INEGI
- Y finamente personalizaremos el gráfico.
Comencemos.
¿Para qué se usan las pirámides de población?
Es la forma más sencilla de entender la dinámica de la población de un lugar.
Es un vistazo al presente y al futuro de la población. Los jóvenes de ahora son los adultos del mañana, que a su vez serán los adultos mayores después. Entender esto de un vistazo te ayuda a proyectar la fuerza laboral, el estado de las pensiones y el futuro de las finanzas públicas.
Entre muchas otras cosas.
Este es el código para hacer una pirámide de población
Esta vez comenzaremos con el código.
Los scripts que te daré te harán el gráfico que buscas en python y R. Sólo tienes que modificar las cifras y los rangos, si es necesario.
Copia este código y úsalo en un script de python. También puedes usarlo en Google Colab.
El único módulo que necesitamos es matplotlib.
# Importamos las librerías necesarias
import matplotlib.pyplot as plt
# Definimos los datos manualmente
rangos_edades = ['0 - 5', '6 - 10', '11 - 15', '16 - 20', '21 - 25', '26 - 30', '31 - 35', '36 - 40', '41 - 45', '46 - 50', '51 - 55', '56 - 60', '61 - 65', '66 - 70', '71 - 75', '76 - 80', '81+']
hombres = [-30320, -24326, -20658, -19694, -16580, -13560, -10634, -8900, -7386, -6094, -4984, -4084, -3284, -2504, -1824, -1284, -896]
mujeres = [29144, 22493, 19878, 21686, 16947, 14374, 12220, 10800, 9634, 8056, 6804, 5634, 4512, 3500, 2642, 1904, 1208]
# Creamos la figura y los ejes
plt.figure(figsize=(10, 8))
# Graficamos la población masculina (lado izquierdo) y femenina (lado derecho)
plt.barh(rangos_edades, hombres, label='Hombres', color="#154957")
plt.barh(rangos_edades, mujeres, label='Mujeres', color="#05cd86")
# Añadimos etiquetas y título en español
plt.xlabel('Población')
plt.ylabel('Rango de Edad')
plt.title('Pirámide Poblacional para el año 1900')
plt.legend(loc='upper right')
# Mostramos el gráfico
plt.show()
Para hacer lo mismo en R, usamos este código. Nota que, como le estamos dando las cifras directamente en el código, no es necesario cargar ninguna base de datos (eso lo haremos más adelante con los datos del INEGI).
# Instalamos (si es necesario) y cargamos la librería ggplot2
if (!require(ggplot2)) install.packages("ggplot2")
library(ggplot2)
# Definimos los datos manualmente
rangos_edades <- c("0 - 5", "6 - 10", "11 - 15", "16 - 20", "21 - 25",
"26 - 30", "31 - 35", "36 - 40", "41 - 45", "46 - 50",
"51 - 55", "56 - 60", "61 - 65", "66 - 70", "71 - 75",
"76 - 80", "81+")
hombres <- c(-30320, -24326, -20658, -19694, -16580, -13560, -10634, -8900, -7386,
-6094, -4984, -4084, -3284, -2504, -1824, -1284, -896)
mujeres <- c(29144, 22493, 19878, 21686, 16947, 14374, 12220, 10800, 9634,
8056, 6804, 5634, 4512, 3500, 2642, 1904, 1208)
# Creamos un data frame con los datos
datos <- data.frame(
RangoEdad = factor(rangos_edades, levels = rev(rangos_edades)), # Invertimos los niveles
Hombres = hombres,
Mujeres = mujeres
)
# Transformamos los datos a un formato largo para ggplot
datos_largo <- reshape2::melt(datos, id.vars = "RangoEdad", variable.name = "Genero", value.name = "Poblacion")
# Creamos la pirámide poblacional
ggplot(datos_largo, aes(x = Poblacion, y = RangoEdad, fill = Genero)) +
geom_bar(stat = "identity", width = 0.8) +
scale_x_continuous(labels = abs, name = "Población") + # Etiquetas del eje x como valores absolutos
labs(y = "Rango de Edad", title = "Pirámide Poblacional para el año 1900") +
scale_fill_manual(values = c("Hombres" = "#154957", "Mujeres" = "#05cd86")) + # Colores para cada género
theme_minimal() +
theme(legend.position = "top") +
guides(fill = guide_legend(title = "Género"))
Debes de obtener como resultado un gráfico como este:
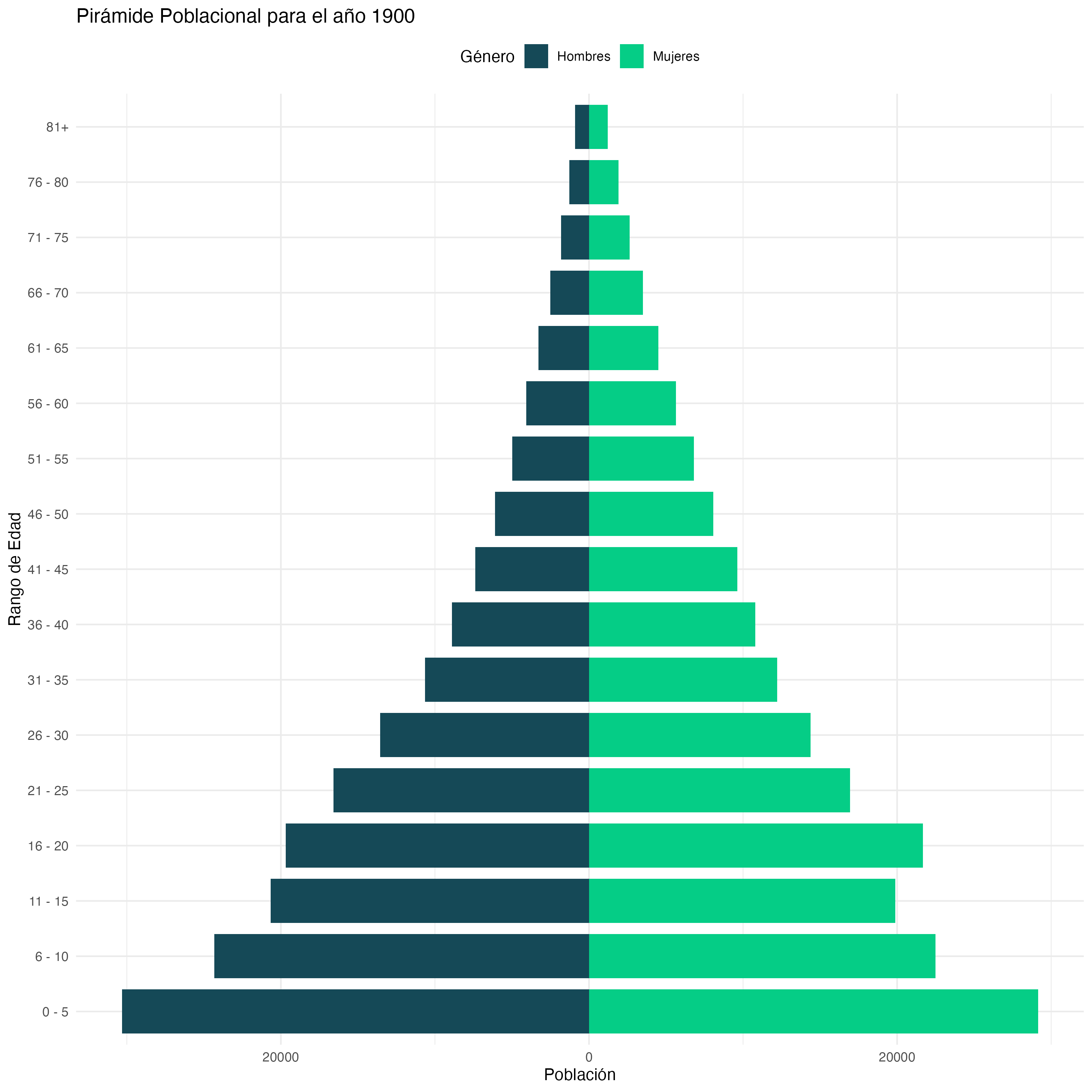
El truco en ambos casos es proporcionar los datos de un género en positivo y los otros en negativo.
Si ya tienes los datos y ya organizaste las sumas, basta con que cambies los números en el código y ya tienes el gráfico listo para usar.
Pero ¿qué hacer con los datos como vienen en el censo?
Hagámoslo.
Tutorial para hacer una pirámide de población con los datos del INEGI en R y Python
Normalmente no nos vamos a encontrar los datos listos para hacer nuestra gráfica.
Generalmente es necesario ordenar los datos y limpiarlos antes de comenzar a hacer los gráficos. Afortunadamente, tanto R como Python tienen funciones que facilitan mucho el trabajo. El código que te voy a pasar funciona sin cambios para el censo 2020 de México en Inegi. Si deseas usarlo en otras bases de datos, lo puedes hacer con cambios ligeros.
No te preocupes, te guiaré en el camino.
Si ya estás listo, comienza por aquí.
Paso #1: Descarga la base de datos
Para este ejemplo usaremos el censo 2020 de Inegi.
Entra el la siguiente página y descarga los tabulados del cuestionario básico de población.
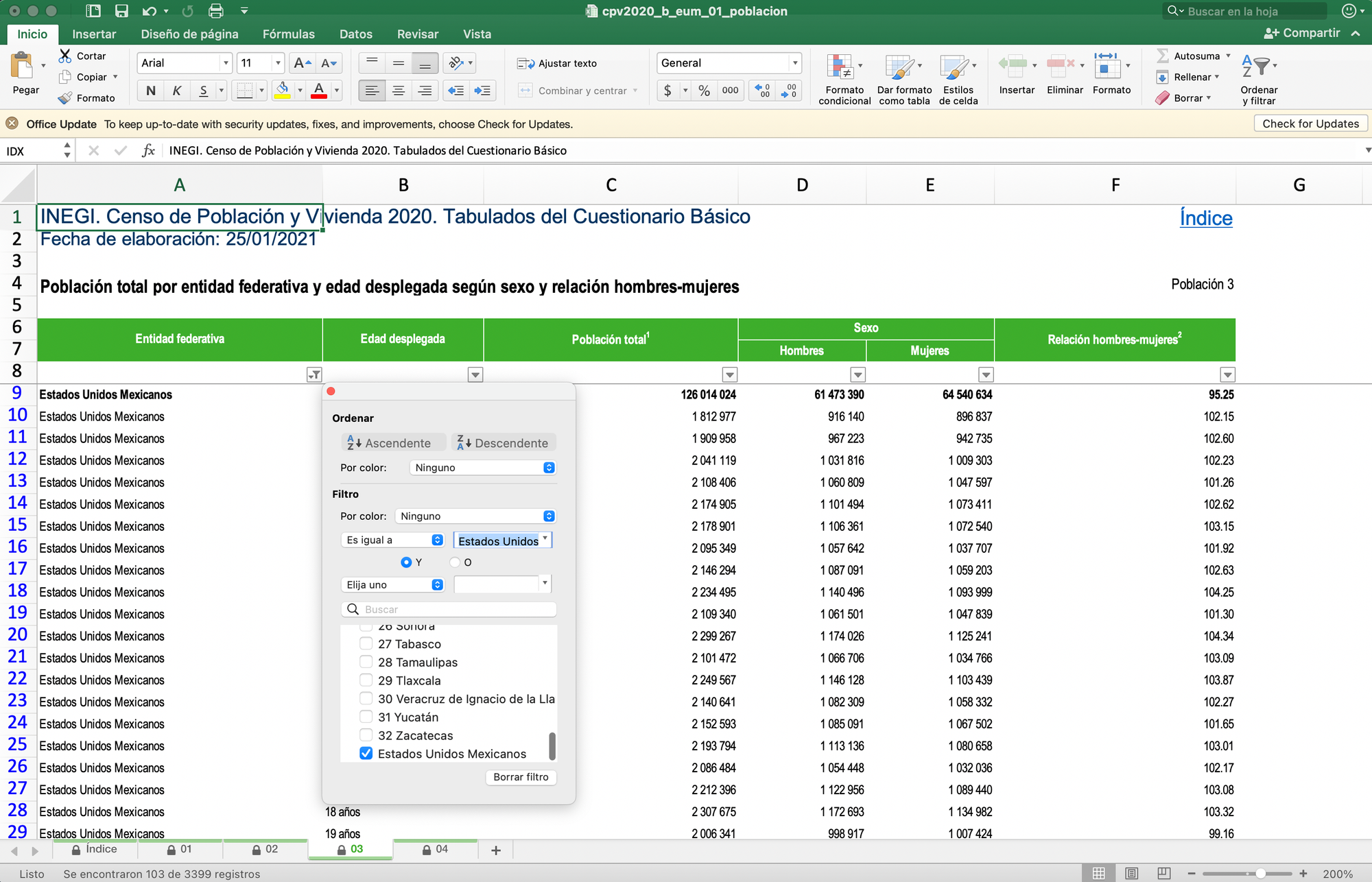
La hoja 03 contiene los datos que buscamos. Los únicos detalles son que hay que filtrar el estado que queremos que nos muestre y que nos arroja todas las edades. Para hacer una pirámide que sea fácil de leer, necesitamos dividir estos datos en rangos.
Así se ve la pantalla de los datos en Excel.
Paso #2: Carga la base de datos en Python/R
Ahora que tienes el archivo descargado, es momento de cargarlo en tu entorno de trabajo. Te mostraré cómo hacerlo tanto en Python como en R, y te explicaré cada paso para que entiendas lo que estamos haciendo y cómo puedes adaptar el código a tus necesidades.
Cargando los datos en Python
Primero, asegúrate de tener instaladas las librerías necesarias. En este caso, usaremos pandas para manejar los datos y matplotlib para las gráficas.
# Importamos las librerías necesarias
import pandas as pd
import matplotlib.pyplot as plt
Ahora, especifica la ruta al archivo que descargaste y el nombre de la hoja que contiene los datos que necesitamos (en este caso, la hoja "03").
# Especifica la ruta al archivo y el nombre de la hoja
file_path = 'ruta/a/tu/archivo.xlsx' # Reemplaza con la ruta real de tu archivo
sheet_name = '03' # Nombre de la hoja que contiene los datos
Leemos los datos del archivo Excel, omitiendo las primeras filas que contienen metadatos y no nos sirven para el análisis.
# Leemos la hoja de Excel, omitiendo las primeras 5 filas de metadatos
data = pd.read_excel(file_path, sheet_name=sheet_name, skiprows=5)
Renombramos las columnas para facilitar su manejo.
# Renombramos las columnas para mayor claridad
data.columns = ["Entidad", "Edad", "Poblacion_Total", "Hombres", "Mujeres", "Relacion_H_M"]
Cargando los datos en R
En R, utilizaremos el paquete readxl para leer archivos Excel y ggplot2 para las gráficas. Asegúrate de tenerlos instalados.
# Instalamos y cargamos los paquetes necesarios
if (!require("readxl")) install.packages("readxl")
if (!require("ggplot2")) install.packages("ggplot2")
library(readxl)
library(ggplot2)
Especifica la ruta al archivo y el nombre de la hoja.
# Especifica la ruta al archivo y el nombre de la hoja
file_path <- "ruta/a/tu/archivo.xlsx" # Reemplaza con la ruta real de tu archivo
sheet_name <- "03" # Nombre de la hoja que contiene los datos
Leemos los datos, omitiendo las primeras filas innecesarias.
# Leemos la hoja de Excel, omitiendo las primeras 5 filas de metadatos
data <- read_excel(file_path, sheet = sheet_name, skip = 5)
Renombramos las columnas.
# Renombramos las columnas para mayor claridad
colnames(data) <- c("Entidad", "Edad", "Poblacion_Total", "Hombres", "Mujeres", "Relacion_H_M")
Paso #3: Filtra y limpia los datos
Los datos que hemos cargado incluyen información de todas las entidades federativas y edades individuales. Para nuestra pirámide poblacional, vamos a enfocarnos en el nivel nacional. Pero si deseas analizar un estado específico, como Durango, te mostraré cómo hacerlo.
Filtrando los datos en Python
Primero, filtramos los datos para quedarnos solo con la entidad que nos interesa. Para el nivel nacional, la entidad se llama "Estados Unidos Mexicanos".
# Filtramos para quedarnos solo con los datos nacionales
filtered_data = data[data["Entidad"] == "Estados Unidos Mexicanos"]
Si quisieras analizar los datos de Durango, simplemente cambia el nombre de la entidad:
# Para filtrar los datos de Durango
filtered_data = data[data["Entidad"] == "Durango"]
Luego, eliminamos filas innecesarias y limpiamos la columna de edad.
# Eliminamos filas con valores NaN en 'Edad'
filtered_data = filtered_data.dropna(subset=["Edad"])
# Excluimos la fila que contiene el 'Total' de la población
filtered_data = filtered_data[filtered_data["Edad"] != "Total"]
# Eliminamos el texto ' años' de la columna 'Edad' para poder convertirla a numérico
filtered_data["Edad"] = filtered_data["Edad"].str.replace(" años", "", regex=False)
Ahora, convertimos las columnas a tipo numérico para poder trabajar con ellas.
# Convertimos las columnas a numérico
filtered_data["Edad"] = pd.to_numeric(filtered_data["Edad"], errors='coerce')
filtered_data["Hombres"] = pd.to_numeric(filtered_data["Hombres"], errors='coerce')
filtered_data["Mujeres"] = pd.to_numeric(filtered_data["Mujeres"], errors='coerce')
# Eliminamos filas con valores NaN resultantes de la conversión
filtered_data = filtered_data.dropna(subset=["Edad", "Hombres", "Mujeres"])
Filtrando los datos en R
Al igual que en Python, filtramos los datos para quedarnos con la entidad deseada.
# Filtramos para quedarnos solo con los datos nacionales
filtered_data <- subset(data, Entidad == "Estados Unidos Mexicanos")
# Si deseas los datos de Durango
filtered_data <- subset(data, Entidad == "Durango")
Eliminamos filas innecesarias y limpiamos la columna de edad.
# Eliminamos filas con NA en 'Edad'
filtered_data <- filtered_data[!is.na(filtered_data$Edad), ]
# Excluimos la fila que contiene el 'Total' de la población
filtered_data <- subset(filtered_data, Edad != "Total")
# Eliminamos el texto ' años' de la columna 'Edad' para poder convertirla a numérico
filtered_data$Edad <- gsub(" años", "", filtered_data$Edad)
Convertimos las columnas a numérico.
# Convertimos las columnas a numérico
filtered_data$Edad <- as.numeric(filtered_data$Edad)
filtered_data$Hombres <- as.numeric(filtered_data$Hombres)
filtered_data$Mujeres <- as.numeric(filtered_data$Mujeres)
# Eliminamos filas con valores NA resultantes de la conversión
filtered_data <- na.omit(filtered_data[, c("Edad", "Hombres", "Mujeres")])
Paso #4: Agrupa las edades en intervalos
Para hacer más legible la pirámide, agruparemos las edades en intervalos de 5 años. Si deseas usar un intervalo diferente, puedes modificar este valor.
Agrupando en Python
Creamos una nueva columna que indica el grupo de edad al que pertenece cada registro.
# Definimos el intervalo de agrupación
intervalo = 5 # Puedes cambiar este valor para intervalos diferentes
# Creamos la columna 'Grupo_Edad' con intervalos de 5 años
filtered_data["Grupo_Edad"] = (filtered_data["Edad"] // intervalo) * intervalo
Agrupamos los datos sumando las poblaciones por grupo de edad.
# Agrupamos y sumamos las poblaciones por grupo de edad
pyramid_data = filtered_data.groupby("Grupo_Edad")[["Hombres", "Mujeres"]].sum().reset_index()
Agrupando en R
Creamos la columna del grupo de edad.
# Definimos el intervalo de agrupación
intervalo <- 5 # Puedes cambiar este valor para intervalos diferentes
# Creamos la columna 'Grupo_Edad' con intervalos de 5 años
filtered_data$Grupo_Edad <- floor(filtered_data$Edad / intervalo) * intervalo
Agrupamos y sumamos.
# Agrupamos y sumamos las poblaciones por grupo de edad
library(dplyr)
pyramid_data <- filtered_data %>%
group_by(Grupo_Edad) %>%
summarise(Hombres = sum(Hombres), Mujeres = sum(Mujeres))
intervalo a 10 en el código anterior. Esto te dará grupos como 0-9, 10-19, etc.Paso #5: Ordena los datos para el gráfico
Queremos que las edades más jóvenes aparezcan en la parte inferior de la pirámide.
Ordenando en Python
# Ordenamos los datos de mayor a menor edad para que las edades más jóvenes queden abajo
pyramid_data_sorted = pyramid_data.sort_values(by="Grupo_Edad", ascending=False)
Ordenando en R
# Ordenamos los datos de mayor a menor edad
pyramid_data <- pyramid_data %>%
arrange(desc(Grupo_Edad))
Paso #6: Grafica la pirámide poblacional
Ahora, vamos a visualizar los datos. Te mostraré cómo personalizar el gráfico y qué aspectos puedes modificar.
Graficando en Python
Configuramos el tamaño de la figura y graficamos las barras para hombres y mujeres.
import matplotlib.pyplot as plt
# Configuramos el tamaño de la figura
plt.figure(figsize=(10, 8))
# Graficamos las barras horizontales para Hombres y Mujeres
plt.barh(pyramid_data_sorted["Grupo_Edad"], -pyramid_data_sorted["Hombres"], label="Hombres", color="#154957")
plt.barh(pyramid_data_sorted["Grupo_Edad"], pyramid_data_sorted["Mujeres"], label="Mujeres", color="#05cd86")
Personalizamos las etiquetas del eje Y para mostrar los intervalos de edad.
# Creamos etiquetas de grupo de edad
etiquetas_edad = [f"{int(edad)}-{int(edad + intervalo - 1)}" for edad in pyramid_data_sorted["Grupo_Edad"]]
plt.yticks(pyramid_data_sorted["Grupo_Edad"], etiquetas_edad)
Añadimos etiquetas y título al gráfico.
# Añadimos etiquetas y título
plt.xlabel("Población")
plt.ylabel("Grupo de Edad")
plt.title("Pirámide Poblacional")
plt.legend()
# Mostramos el gráfico
plt.tight_layout()
plt.show()
Personalización:
- Colores: Puedes cambiar los colores modificando los valores en
color. Por ejemplo,color="skyblue"para Hombres ycolor="pink"para Mujeres. - Título y etiquetas: Modifica el texto dentro de
plt.title(),plt.xlabel(), yplt.ylabel()para reflejar tu análisis. - Tamaño de la figura: Cambia el tamaño en
plt.figure(figsize=(ancho, alto))si quieres un gráfico más grande o más pequeño.
Graficando en R
Usamos ggplot2 para crear el gráfico.
library(ggplot2)
# Creamos el gráfico de la pirámide poblacional
ggplot(pyramid_data, aes(x = Grupo_Edad)) +
# Barras para Hombres (valores negativos para orientarlas a la izquierda)
geom_bar(aes(y = -Hombres), stat = "identity", fill = "#154957", width = intervalo - 1) +
# Barras para Mujeres
geom_bar(aes(y = Mujeres), stat = "identity", fill = "#05cd86", width = intervalo - 1) +
# Configura las etiquetas de los grupos de edad
scale_x_continuous(breaks = pyramid_data$Grupo_Edad, labels = paste0(pyramid_data$Grupo_Edad, "-", pyramid_data$Grupo_Edad + intervalo - 1)) +
# Ajusta las etiquetas del eje Y para mostrar valores absolutos
scale_y_continuous(labels = abs, name = "Población") +
# Añade título y etiquetas
labs(title = "Pirámide Poblacional", x = "Grupo de Edad") +
# Invierte los ejes para que las edades más jóvenes estén abajo
coord_flip() +
theme_minimal() +
theme(legend.position = "top")
Personalización:
- Colores: Cambia los colores en
filldentro degeom_bar(). Por ejemplo,fill = "blue"para Hombres yfill = "red"para Mujeres. - Título y etiquetas: Modifica
labs(title = "Tu Título", x = "Eje X", y = "Eje Y")para personalizar. - Tema del gráfico: Puedes cambiar el tema con
theme_classic(),theme_bw(), etc.
fill en aes() y ajustar la leyenda con scale_fill_manual().Paso #7: Personaliza y analiza tu pirámide
¡Felicidades! Ahora tienes una pirámide poblacional basada en los datos del INEGI.
¿Qué más puedes hacer?
- Cambiar el intervalo de edad: Si deseas grupos más amplios o más específicos, modifica el valor de
intervaloen el paso de agrupación. Por ejemplo, para intervalos de 10 años, estableceintervalo = 10. - Seleccionar otra entidad o región: Puedes filtrar los datos para cualquier estado o municipio cambiando el nombre en el filtro inicial. Asegúrate de que el nombre coincida exactamente con el que aparece en la columna "Entidad".
- Agregar proyecciones o datos históricos: Si tienes acceso a datos de diferentes años, puedes crear pirámides para cada año y compararlas para analizar tendencias demográficas. (Si te interesa más sobre esto, me dices y podemos expander este tutorial)
- Personalizar el diseño del gráfico: Explora más opciones de personalización en
matplotlibyggplot2. Puedes cambiar fuentes, agregar anotaciones, ajustar escalas, entre otros.
Ejemplos de modificaciones:
En R: Cambiar el tema del gráfico.
# Cambiar el tema a clásico
theme_set(theme_classic())
En Python: Añadir una cuadrícula al gráfico.
# Añadir cuadrícula al gráfico
plt.grid(axis='x', linestyle='--', alpha=0.7)
Es tu turno de ponerlo en práctica
Las pirámides poblacionales son herramientas poderosas para entender la estructura y dinámica de una población.
Ahora puedes explorar diferentes escenarios y adaptar el análisis a lo que necesitas hacer.
Recuerda que los datos pueden venir en diferentes formatos y es posible que necesites ajustar el código para manejarlos correctamente. Experimenta y explora más funciones de las librerías que hemos usado.
Si te encuentras con algún problema o tienes dudas, contesta este post y te puedo guiar.